1.0 Introduction:
This
document gives an insight on the process of creating the performance test scripts
for Oracle ADF/Fusion application using HP Loadrunner tool
2.0 Preserving
View State, Controller State, and Other ADF Query Parameters:
ADF
Faces is stateful and maintains state in two places:• View state is preserved in a hidden form field on each page. This hidden form field can either contain an ID that is used to locate its view state on the server (server state saving), or it will contain a hexadecimal encoding of the view state (client state saving)
• Controller state and other session info is preserved as query parameters on the URL (e.g.,_adf.ctrl-state, _afrLoop, _afrWindowMode, _afrWindowId, _afPfm, _rtrnI3.0 Important settings in Recording options:
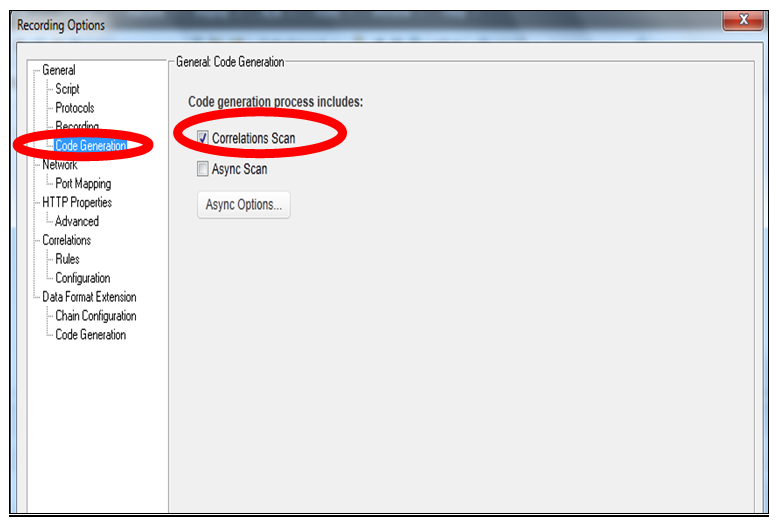
3.0 Important settings in Recording options:
Code Generation

HTTP Properties -> Advanced -> Header
Add the following headers in the recording header list.
Ø Adf-rich-messag
Ø Adf-ads-page-id
Ø Soapaction
Ø User-agent
Ø Authenticate
ØUA-CPU

Import
the following correlation rules (Everest and SFDC)

Correlations
-> Configuration

4.0 Errors and Resolution:
In Oracle ADF application,
verification is done based on the snapshot. Comparing the recorded snapshot and
replaying snapshot. It should be same except the view state values.
Snapshot is
different. Recorded snapshot is XML and replay snapshot is Web Page (Like
below)

Resolution:
Add the following function above the request
Web_add_header(“Adf-Rich-Message”,”true”);

In some test cases, you have to do print which will open a new
browser and it gets recorded in the script as well. While replaying that
request, Snapshot is different looks like below.

Resolution:
Add the following function above the request.
Here “_rtrnId_1” is the correlated value and it captured before this request.
web_add_header("adf-dialog-return-id",lr_eval_string("{_rtrnId_1}"));

JSESSION id is created in controller.jsp request under action.
While replaying the script for multiple iterations, the script will fail after
1st iteration at controller.jsp request saying that “No match found
for JSESSION”
Resolution:
Place
the JSESSION correlation in “IF” loop like below.
if(strcmp("{JSESSION}",lr_eval_string("{JSESSION}")) == 0 )
{
{
web_reg_save_param_ex(
"ParamName=JSESSION",
"LB/IC=\";jsessionid=",
"RB/IC=\";",
SEARCH_FILTERS,
"Scope=Body",
"IgnoreRedirections=Yes",
"RequestUrl=*/controller.jsp*",
LAST);
}
"ParamName=JSESSION",
"LB/IC=\";jsessionid=",
"RB/IC=\";",
SEARCH_FILTERS,
"Scope=Body",
"IgnoreRedirections=Yes",
"RequestUrl=*/controller.jsp*",
LAST);
}

In some requests like copy quote and save quote has unique value
captured while recording which is nothing but epoch time in milliseconds. We
need to replace that value based on the replay time.
Resolution:
Add the following function above the request. web_save_timestamp_param(“EpochTimeStampNow”,LAST);
EpochTimeStampNow is a LR
variable to save the epoch time in milliseconds and it does not need to declare
in script.

There are correlation values like viewstate, viewstatemac,
viewstatecsrf, captured as part of script enhancement. These values are passing
either web_submit_data or web_custom_request. If the values are passing in
web_custom_request, then it needs to be converted to URL format.
Resolution:
Add the
following function above the request.
web_reg_save_param_ex(
"ParamName=viewStateCsrf__1",
"LB/IC=ViewStateCSRF\" value=\"",
"RB/IC=\" />",
SEARCH_FILTERS,
"Scope=Body",
"RequestUrl=*/OPTY_AccountPartnerSelection_New_VP*",
LAST);
"ParamName=viewStateCsrf__1",
"LB/IC=ViewStateCSRF\" value=\"",
"RB/IC=\" />",
SEARCH_FILTERS,
"Scope=Body",
"RequestUrl=*/OPTY_AccountPartnerSelection_New_VP*",
LAST);
Add the following function below the request. web_convert_param("viewStateCsrf__1_URL2",
"SourceString={viewStateCsrf__1}",
"SourceEncoding=HTML",
"TargetEncoding=URL",
LAST);
"SourceString={viewStateCsrf__1}",
"SourceEncoding=HTML",
"TargetEncoding=URL",
LAST);

Hope this post will help you to understand some basics when you start to work in Oracle ADF application performance testing.
Happy reading 😃
Happy reading 😃









